
Wat machine learning met woorden doet
Hoe machine learning wordt ingezet op zogenaamde ‘bag of words’, om er zo voor te zorgen dat computers beter de menselijke taal begrijpen, daarover gaat mijn tweede blog over de Human Assisted Virtual Agent (HAVA).
Waar ik in mijn vorige blog nog besprak hoe menselijke klantmedewerkers en HAVA’s kunnen samenwerken als machine learning en AI-technologie worden toegepast op systemen die klanten moeten ondersteunen, wil ik nu nog een stap verder gaan. Met machine learning moet je veelal zaken vergelijken of juist gelijktrekken. Als je bijvoorbeeld naar een goed antwoord in een database zoekt, moet je de vraag vergelijken met de verschillende antwoorden die hierin opgeslagen zitten.Voor het sorteren van mogelijke antwoorden in aparte verzamelingen (clusteren), moet je ze met elkaar vergelijken en nagaan hoe gelijk ze zijn.
In veel moderne methoden gebeurt dit door alleen te kijken naar het uiterlijk van woorden en hun volgorde; een handelswijze die inmiddels bekendstaat als ‘bag of words’. Als twee zinnen of teksten uit grofweg dezelfde woorden bestaan dan zijn ze waarschijnlijk gelijk en hebben ze een vergelijkbare betekenis, luidt de gedachte. Deze aanpak werkt wonderlijk goed voor vele taken (klassieke internetzoektechnieken vertrouwen op deze methode), hoewel het wel negeert dat taal uit veel meer bestaat dan zomaar een verzameling woorden. Zinnen hebben een structuur en woorden een betekenis.
Laten we eens kijken naar deze Engelstalige voorbeelden:
1. How do I change the motor oil?
2. Tell me how the engine lubricant gets replaced.
Afhankelijkheidsbomen
Hoewel deze zinnen er op het oog heel anders uitzien, verzoeken ze in feite hetzelfde en is de betekenis eveneens hetzelfde. Mensen verwachten dat een HAVA dit begrijpt. Puur statistische benaderingen lossen zo’n kwestie op door vele duizenden teksten te bekijken en daaruit vast te stellen dat de woorden ‘oil’ en ‘lubricant’ vaak in vergelijkbare context gebruikt worden. Daaruit leert het systeem op impliciete wijze de betekenis van een woord door te kijken naar de context waarin het normaal gesproken gebruikt wordt.
Echter is er ook een aanpak die de structuur en betekenis van taal op een meer expliciete wijze onderzoekt. Met symbolische verwerking kun je de structuur proberen te verkrijgen door een syntaxisboom aan een zin toe te wijzen. Een categorie van zulke structuren, zogeheten afhankelijkheidsbomen, begint met de observatie dat de kern van een zin bestaat uit een werkwoord en dat de andere woorden ‘afhankelijk’ zijn van dit werkwoord; vergelijkbare bijvoeglijke naamwoorden en andere bijvoeglijk bepalende woorden zijn afhankelijk van het zelfstandig naamwoord waar ze naast staan. Eenvoudige afhankelijkheidsbomen voor de voorbeelden 1 en 2 kunnen er als volgt uitzien:
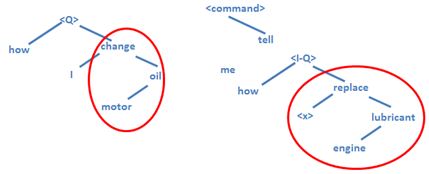
Als je kijkt naar de rood omcirkelde onderdelen, zie je vergelijkbare structuren. Als we weten dat ‘change’ en ‘replace’, ‘oil’ en ‘lubricant’ en ‘motor’ en ‘engine’ hetzelfde betekenen of op zijn minst zeer verwant zijn, dan zijn we er al. In het verleden zijn veel pogingen gedaan zulke verwantschappen vast te leggen en woorden te sorteren in verzamelingen met dezelfde betekenis en deze verzamelingen in hiërarchieën te organiseren. Niet de eerste, maar een bekende poging daartoe was Roget’s Thesaurus. Een moderne, door computers begrijpbare equivalent is WordNet, een verzameling van 155.287 Engelse woorden die op moment van schrijven gekoppeld zijn aan 117.659 concepten. Volgens deze index staat een woord als 'engine' als zusterterm beschreven met 'motor'. In de wereld van WordNet betekent dit dat deze twee termen tot detzelfde ‘synset’ behoren. Ofwel, ze vertegenwoordigen hetzelfde concept . Als we nu woorden door synsets vervangen in onze afhankelijkheidsbomen, worden ze zeer vergelijkbaar of zelfs identiek voor hun relevante gebied. Op die manier kan de vergelijkbaarheid van stukken tekst veel nauwkeuriger gemeten worden (wat we later ook nog zullen zien).
Het gebruik van lexicons en syntactische structuren mag dan old skool overkomen, maar dat hoeft het niet te zijn. Bij Nuance trachten wij symbolische verwerking te combineren met machine learning. Door de ruwe data met syntactische en semantische informatie te verrijken, verandert Big Data veranderd in Big Knowledge. Vervolgens kan dit op HAVA’s worden toegepast om op die manier te zorgen voor een betere klantinteractie. In mijn derde en laatste gastblog voor CustomerFirst verkennen we wat dit betekent voor klantenservice.
Noot: deze gastblog is geschreven door Nils Lenke, senior director Corporate Research bij Nuance Communications.
- machine learning
- Nuance
- spraakherkenning
- Nils Lenke
- afhankelijkheidsbomen
- HAVA
- Big Knowledge
- bag of words















