
Klantkwesties oplossen via machine learning

Hoe kun je 'Big Knowledge’ toepassen voor klantondersteuning? En wat kan worden gedaan om de virtuele klantmedewerker nog slimmer te laten lezen? In dit derde deel van mijn blogserie voor CustomerFirst de antwoorden op bovenstaande.
Als je deze blogserie* hebt gevolgd, dan weet je inmiddels dat artificial intelligence (AI) en machine learning (ML) een flinke invloed kunnen hebben op het bieden van de best mogelijke klantervaring. Ten behoeve van klantondersteuning zetten wij Big Knowledge in, maar waar wat betekent dit?
De eerste taak waar ik het over wil hebben, is het vinden van relevante tekstgedeelten die het antwoord op een vraag bevatten. Dit wordt ook wel passage retrieval genoemd. Wanneer klanten een vraag stellen over een onderwerp dat al in de databank staat, kan dankzij passage retrieval eenvoudig de juiste ondersteuning worden geboden. En in plaats van te zoeken naar alleen woorden en daarbij hopen dat de klant dezelfde bewoording/taal gebruikt, zullen we in het laatste deel van dit bericht toepassen wat we geleerd hebben.
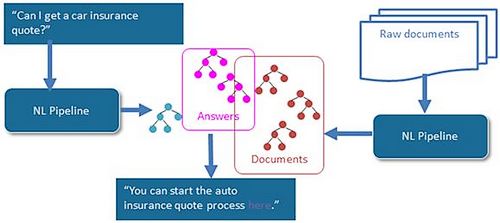
Zoals bovenstaand diagram laat zien, is het de truc om zowel de database van documenten als de vraag via Natural Language te laten lopen en daarbij verbeterde afhankelijkheidsbomen te genereren. Het samenstellen van een index van dergelijke bomen gebeurt offline, terwijl de vraag real-time wordt verwerkt. De best passende bomen worden geselecteerd als antwoord en de tekstpassages vervolgens gerangschikt, waarna de klant de beste combinatie krijgt aangereikt. Een test bij één van onze klanten toonde aan dat deze aanpak veel beter werkt dan hun oudere onderzoeksmethode, die was gebaseerd op het traditionele zoeken op woordniveau. De oude tool werkte redelijk goed wanneer klanten gebruikmaakten van de juiste zoekwoorden (dit leverde in 84% van de gevallen het juiste antwoord op), maar werkte beduidend minder goed als mensen zoekopdrachten gaven in natuurlijke taal (in 54% van de gevallen werd het juiste antwoord gevonden).
Clustering
Op dezelfde manier zetten we deze methode nu in voor een andere typische machine learning-taak, namelijk clustering. Eerder gaf ik al aan dat klanten verschillende intenties (of een groep van intenties) hebben wanneer ze contact opnemen met klantenservicemedewerkers. Maar hoe weten we welke groepen intenties bestaan? Een handmatige analyse is zeer tijdrovend. Je kunt er ook voor kiezen om machine learning in te zetten om clusters te identificeren van dingen die op elkaar lijken vergeleken met de rest van de informatie. Stel je bestudeert 100.000 binnenkomende vragen; is het dan mogelijk om 100, 200 of 500 groepsintenties te vinden die je kunt toewijzen aan de verschillende vragen? Doe je dit automatisch, dan kun je eenvoudig monitoren hoe verzoeken in de loop der tijd veranderen. De klantbehoefte verandert immers ook steeds.
Customer experience
Een andere aanpak (de meer naïeve aanpak), is om standaard machine learning clustering in te zetten op de eerste verzoeken van klanten. Op mondiaal niveau. Echter, gezien het besprokene in deze blogserie kunnen we dit op twee manieren verbeteren. Allereerst spreken we niet alleen de eerste gebruiker, maar in plaats daarvan bekijken we het hele plaatje. Net als de menselijke (en virtuele) klantmedewerkers moet de gehele interactie in beschouwing worden genomen, als we starten met clusteren. Ten tweede zetten we onze Natural Language-pijplijn in om gewone woorden om te zetten in semantisch uitgebreide afhankelijkheidsbomen. Aansluitend worden de clustering algoritmen hierop losgelaten. Beide benaderingen helpen ons bij het verkorten van de tijd die we besteden aan het maken van aantekeningen voordat we een technologie in gebruik nemen. Daarnaast stellen ze ons in staat om gebruik te maken van de ongestructureerde gegevens die vele bedrijven al beschikbaar hebben. De virtuele assistent is niet alleen bruikbaar voor de eindgebruiker, maar biedt bovendien hulp om ongestructureerde data van bedrijven te vertalen naar de juiste soort gelabelde big data, waarmee de virtuele agent een stap zet in de richting van grensverleggende kennis over AI.
Resumerend resulteert Big Knowledge in grote veranderingen voor de klantondersteuning middels human assisted virtual agents (HAVAs). Met de juiste beschikbare methoden kunnen ze de samenwerking tussen mensen en machines vergroten om een effectieve en efficiënte klantervaring te creëren voor mensen over de hele wereld.
Noot: deze gastblog is geschreven door Nils Lenke, senior director Corporate Research bij Nuance Communications.
* Lees hier deel 1 en deel 2 van zijn blogserie.
- clustering
- Nuance
- passage retrieval
- Nils Lenke
- Big Knowledge
- customer experience
- klantkwesties
- HAVA
- machine learning
- kunstmatige intelligentie















